Data Engineering, Big Data, and Other Vague Vocabulary
The cross-section of software engineering and data science is home to an unusual culture of gatekeeping.


I've spent the majority of my life dreading an eternal question that governs our lives. You know the one. It's the one that comes after our ritualistic handshakes and "nice to meet you"s. The one that summarizes our place in society, in 5 words or less: "what do you?"
Most managers never seem to have this problem. My previous peers in product or engineering management roles had little trouble letting others fill in the blanks for them, but I've never been one comfortable with accepting hyperbolic inferences. For non-producing members of skilled teams, I doubt the integrity of one who nods in response to "oh, so you're the boss?" I instead relived groundhog day eternally, watching the progression where an acquaintance's eagerness to care deteriorates into realizing they don't.
A lifetime later, I landed my first title as a data engineer, and boy did that feel great! After years of enduring the cocktail-party-existential-crises, I had a real title. Fine, "manager" is a title, but this title had tangible substance! The first chance I had to introduce myself as a Data Engineer happened to be in Ibiza, in all places. As it turns out, an American stranded in Spain making friends with somebody from Bosnia has its language barriers, so the phrase "data engineer" wasn't quite translating well. The best stand-in explanation I could find was "hacker."
Data Engineers Are Definitely Not Hackers
I had a lot of assumptions about what it meant to be a "data engineer" going into it, and none of them were particularly outrageous. I'd had my hand in software development for over ten years at the time. The boom of mainstream data science bit be like a bug, like the rest of us, and something about the problems we could solve seemed to make software fun again. We weren't building worthless landing pages, or tired login screens. Instead, we could write sports betting algorithms, or mine the world's unprotected data. I already loved engineering like I loved Oreos, and this particular flavor of engineering felt like taking two Oreos apart and stick them back together: less of the lame stuff, more of the awesome stuff.
Data Engineering isn't really Software Engineering
Obviously you need to be a software engineer to some capacity to be a data engineer. That said, the concerns of data engineers fall further away from the tree than I ever initially anticipated.
Most programming work I engaged in before data revolved heavily around algorithms, whether I realized it at the time or not. Building consumer and business-facing products entails more moving parts than any single human can account for. Software worth using is an effort between many people accountable for many services, which make up some abstract entity used by vast quantities of unreasonable people (I kid). The challenge of engineering something complex comes in the clever decisions we make to leverage simplicity. The first time I ever dissected a Walkman, or took the lid off a toilet, or taken apart a mechanical pen, the reaction is always the same: "that's it?" And yet, "that's quite genius."
A Day In The Life
The skills and duties of data engineering teams zero consistency between companies. Some shops integrate data engineers with data scientists and analysts to supplement those teams. Other companies have massively siloed "big data" teams, which are almost always made up of Java developers who have seemingly found a comfortable (and lucrative) niché, forever married to MapReduce without the burdens of cross-department communication. Unfortunately, this scenario is far more common.
Most of a data engineer’s responsibilities revolve around ETL: the art of moving data from over there to over here. Or, perhaps also there. And yet, likely here, there, and there (and oh yeah, it nothing is allowed to break, even though those things are different). The concept feels straightforward. It is. We're also dealing with incomprehensibly massive amounts of data, so it's also repetitively stressful. Straightforward and stressful aren't the sexiest adjectives to live by.
Tools Over Talent
Luckily for us, our company isn't the first company to work with data- that’s where our predetermined catalog of “big data” tools comes in. No matter how different data teams are between companies, the inescapable common ground is that data Engineering is largely about tools. We’re talking Apache Hadoop, Apache Spark, Apache Kafka, Apache Airflow, Apache 2: Electric Boogaloo, and so forth.
Working with each of these things is a proprietary skill of its own. PySpark is essentially its own language masquerading as Python. Hadoop's complexity serves little purpose other than to ensure old school data engineers have jobs. Each of these tools are behemoths, each of which was created to do a very specific thing in a very specific way. Becoming adept at Spark doesn’t make you a better engineer, or a problem solver: it just makes you good at using Spark. Airflow is a powerful tool for organizing and building data pipelines. With all it’s included bells and whistles, Airflow offers teams power and structure at no cost. It’s obvious that Airflow (and equivalent) are “the right tool” upon using it, but structure comes at a price to human beings. It’s only a matter of time before I’m aware I’m mindlessly executing things in the only possible fashion they might be executed. Unlike building complex systems, it feels like data engineering only has so much room for clever optimization.
This doesn’t seem so bad to a 9-5 worker looking to live their non-office lives: hoarding lucrative knowledge is an easy way to pay the bills. What bothers me is this mindset can only prevail if the person harnessing does not actually enjoy programming. In every software engineering interview I've ever had, there's inevitably been some sort of hour-long algorithm whiteboard session where you optimize your brute force O(n^2) algorithm to O(n). While those are stressful, people who enjoy programming usually walk out of those interviews feeling like they enjoyed it. I've never been asked an algorithm question in a data engineering interview. Those go more like this:
- Have you ever had a situation where you had to configure a Kafkta instance using the 76C-X configuration variable on the 27 of May during a full moon?
- I see you've worked with SQS, Kinesis, Kafka, Pub/Sub, and RabbitMQ, but have you ever worked with [obscure equivalent service this company uses, with the implication that it isn't exactly the same]
- I know you're not too hot on Hadoop, but can you tell me about the inner workings of this specific feature before it was depreciated 3 years ago anyway?
- I'm running a PC with 4 cores and 16 gigs of ram, looking to parse a 200,000-line JSON file while vacationing with my family in Aruba. Which Python library would you use to engage Python's secret Hyperthreaded Voltron I/O Super Saiyan skill, and what kind of load would my machine be under as a result?
I'm barely kidding about these... even the last one. If Silicon Valley's primary hiring philosophy prioritizes smart people who can learn, data engineering interviews measure whether your wealth of useless trivia is culturally acceptable by people who value that sort of thing.
We Need To Address "Big Data"
I've been making some vast generalizations so far. I don't truly believe all data engineers share the same personality traits. In fact, there are at least two kinds of data people in this world: people who say "big data" unironically, and those who don't. I'm the latter. The complaints I have about our profession are directed at the former.
There's a big difference between a startup looking to "revolutionize the world with AI," and startups looking to leverage machine learning to optimize a case where it makes sense. Given the cheapness and implied misunderstanding of the term, simply hearing the phrase "AI" in a conversation has me questioning credibility. Don't get me started on Blockchain.
Big data has no actual definition other than "a lot of data." Trying to track down the origins of the phrase results in endless pages of data companies spewing absurd jargon (and hilariously copy+pasted definitions from one another), proudly aligning themselves with the new world order of Big Data. One article titled "A Brief History of Big Data" starts at the year 18,000 BCE. Get over yourselves.
In reality, the phrase "Big Data" started to pick up pace around 2012:
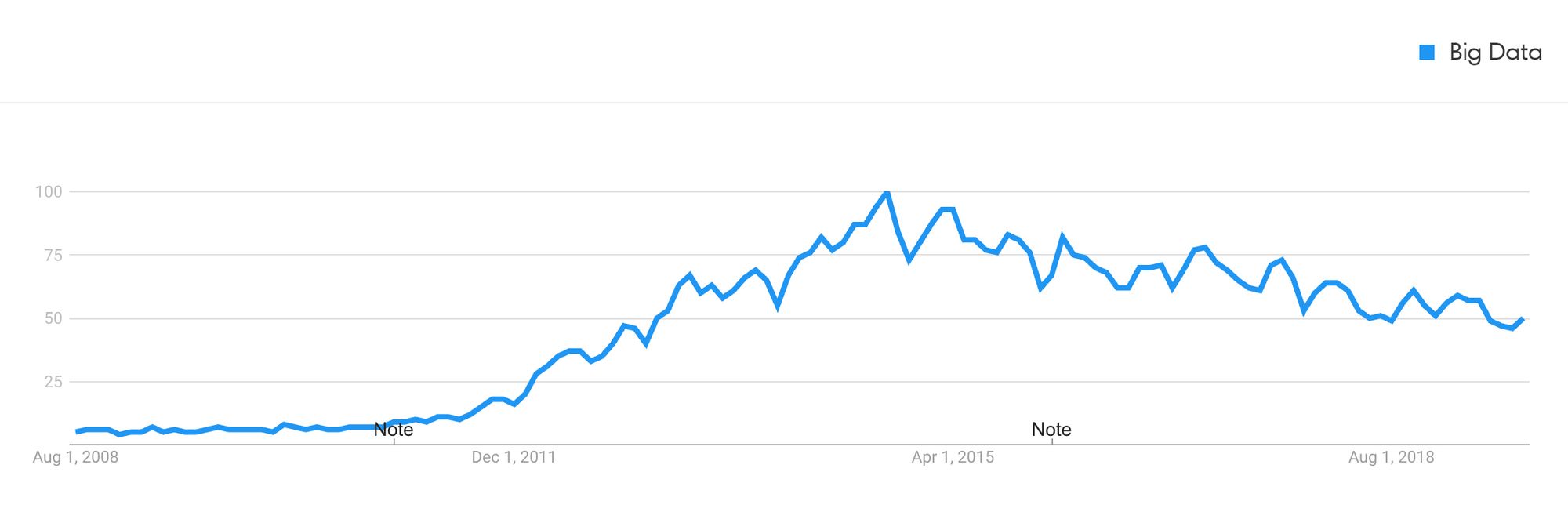
We have Doug Laney to blame for coining the phrase in 2001, but if I had to guess, the trend seems much more closely correlated with the rise of Hadoop:
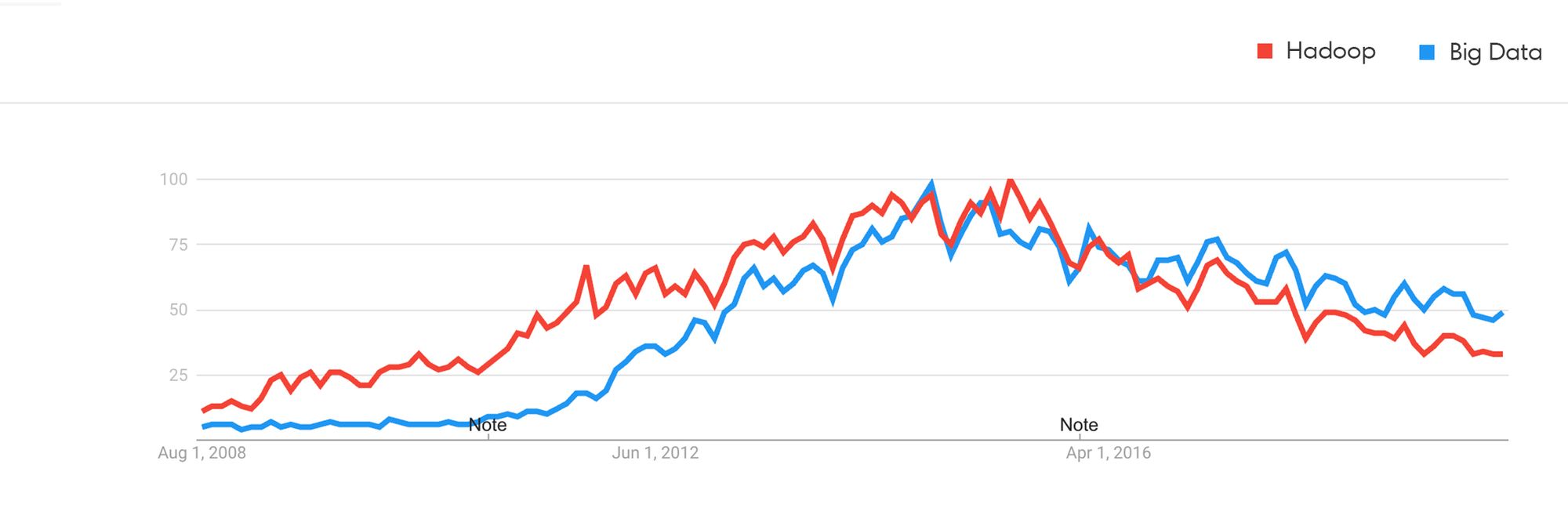
Hadoop enabled companies to work with and process much larger data than before, thus "Big Data" was technically relatively accurate. Java was by far the most common programming language being learned by new developers, being the de facto choice for school curriculum and general programming. I imagine it was an easy choice for many to double down on the language they knew by leveraging their knowledge and being Hadoop subject-matter experts. That's twice the job security and twice the skills!
Most people I know who overly emphasize their "big data" expertise are in fact Java/Hadoop guys. They're quick to ask how many petabytes or exabytes of data your last pipeline ran, fiercely keeping the gate open for only the Biggest of Data. They don't want to learn new programming languages. They don't want to see which data warehouse best fits their needs by reading the whitepapers. They don't want to question if it's really necessary for a cluster of hundreds of nodes to run small nightly jobs. They want to cling to a time where they made two good consecutive life decisions and partied to the Big Data anthem.
Bigger Doesn't Mean Better
Some data engineers are exactly what their titles imply: engineers with a specialty in data. On the other side of this, there's a rampant culture of gatekeeping and self-preservation which is almost certainly destroying company budgets in ways which aren't visible.
Data engineering teams with head-counts in the double-digits clock 8 hours a day, over-implementing systems too obsolete to turn profits for Cloudera, Hortonworks, or MapR. If these teams had consisted of software engineers as opposed to big data engineers, we would have teams focused on creating the best solutions over the easiest ones.